2026-03-08
Introduction
The aim of this project is to develop simple models that can recognise handwritten characters. The models can recognise the following Latin alphabet characters:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
as well as the following Japanese hiragana characters:
あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん
For the Latin characters, although lowercase characters are also recognised, these are grouped together with the uppercase characters.
As well as actually working on the models, another important goal of this project is to sexperiment with adding more interactive features to the website.
Demo
mnist-large: the better-performing model
mnist-small: the much more compact and fast model
Development
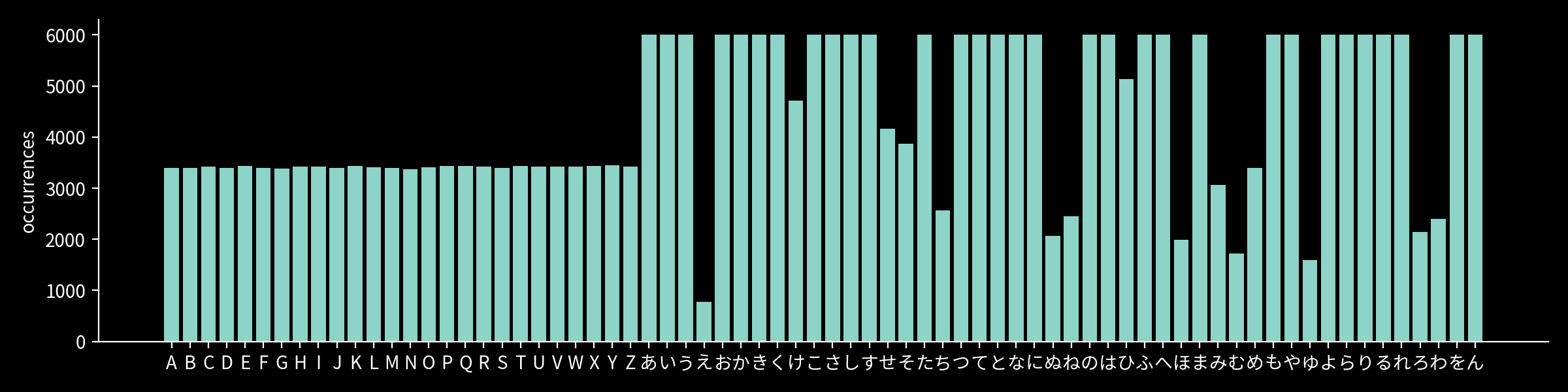
The datasets used to train the models are the following:
- EMNIST (Balanced Letters) for the Latin characters
- KMNIST (Kuzushiji-49) for the hiragana characters
After combining, the occurrences of each character in the datasets are as follows:
For training, the following was used:
- optimiser: Adam, with a learning rate of 0.001
- loss function: cross-entropy loss, weighted by the inverse frequency of each character
- epochs: 50
- batch size: 1024
Two CNN models were developed:
mnist-large (see architecture)
and
mnist-small (see architecture).
Both models use a similar architecture, consisting of a combination of Conv → ReLU → MaxPool layers and fully connected
layers. Both models also use dropout layers to reduce overfitting.
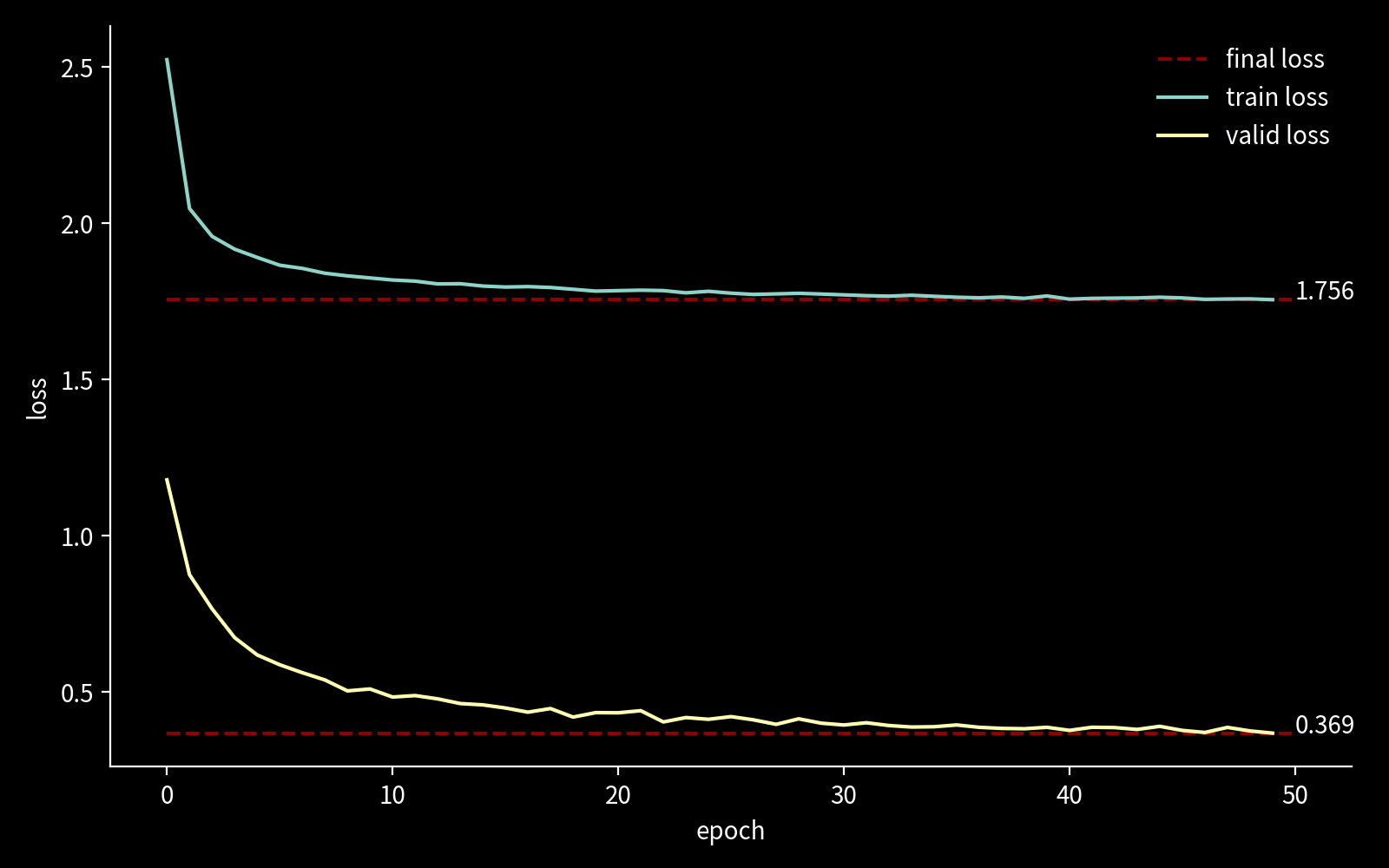
The following plot shows the training loss for mnist-large:
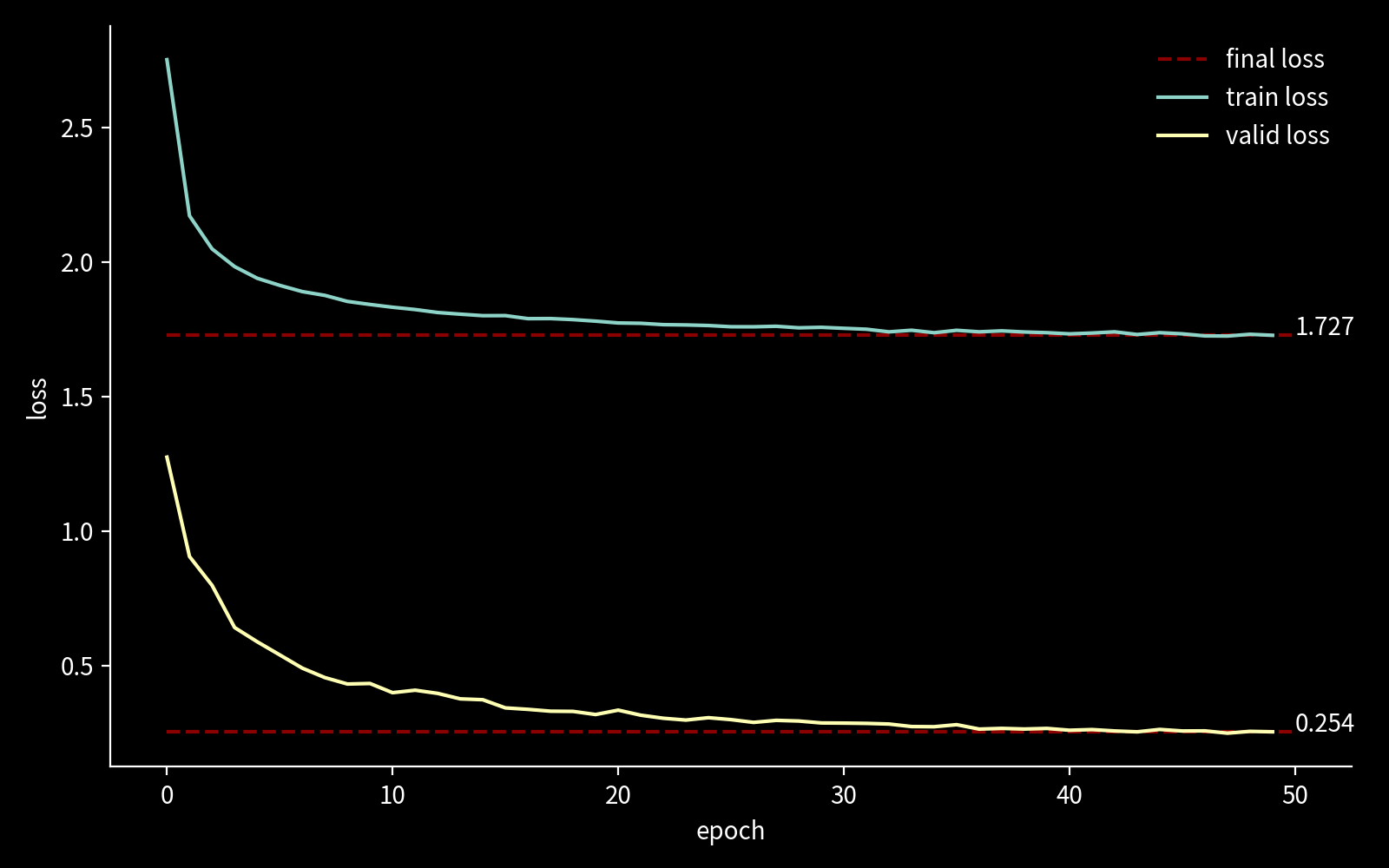
and the following plot shows the training loss for mnist-small: